Critical flaw in OpenAI Codex could lead to theft of GitHub tokens through command injection, report reveals
Published on: 2026-03-30
AI-powered OSINT brief from verified open sources. Automated NLP signal extraction with human verification. See our Methodology and Why WorldWideWatchers.
Intelligence Report: OpenAI Codex vulnerability enabled GitHub token theft via command injection report finds
1. BLUF (Bottom Line Up Front)
A critical vulnerability in OpenAI’s Codex coding agent allowed for potential GitHub token theft via command injection, posing significant risks to enterprise environments. The vulnerability has been addressed by OpenAI, but the incident underscores the security challenges of integrating AI agents into development workflows. The most likely hypothesis is that the vulnerability was an unintended flaw rather than a targeted attack. Overall confidence in this assessment is moderate.
2. Competing Hypotheses
- Hypothesis A: The vulnerability was an unintended flaw in Codex’s design, resulting from inadequate input validation and shell command handling. This is supported by the quick response and remediation by OpenAI, suggesting a lack of malicious intent. However, the extent of potential exploitation remains uncertain.
- Hypothesis B: The vulnerability was exploited as part of a targeted attack to gain unauthorized access to GitHub repositories. This hypothesis lacks direct evidence but cannot be ruled out given the potential for significant organizational compromise.
- Assessment: Hypothesis A is currently better supported due to the absence of evidence indicating a targeted attack and the swift corrective actions taken by OpenAI. Indicators such as evidence of coordinated exploitation or insider involvement could shift this judgment.
3. Key Assumptions and Red Flags
- Assumptions: OpenAI’s remediation measures are effective; the vulnerability was not widely exploited before detection; Codex’s integration into workflows is secure post-fix.
- Information Gaps: Details on whether any unauthorized access occurred prior to the fix; the scope of permissions granted to Codex in enterprise environments.
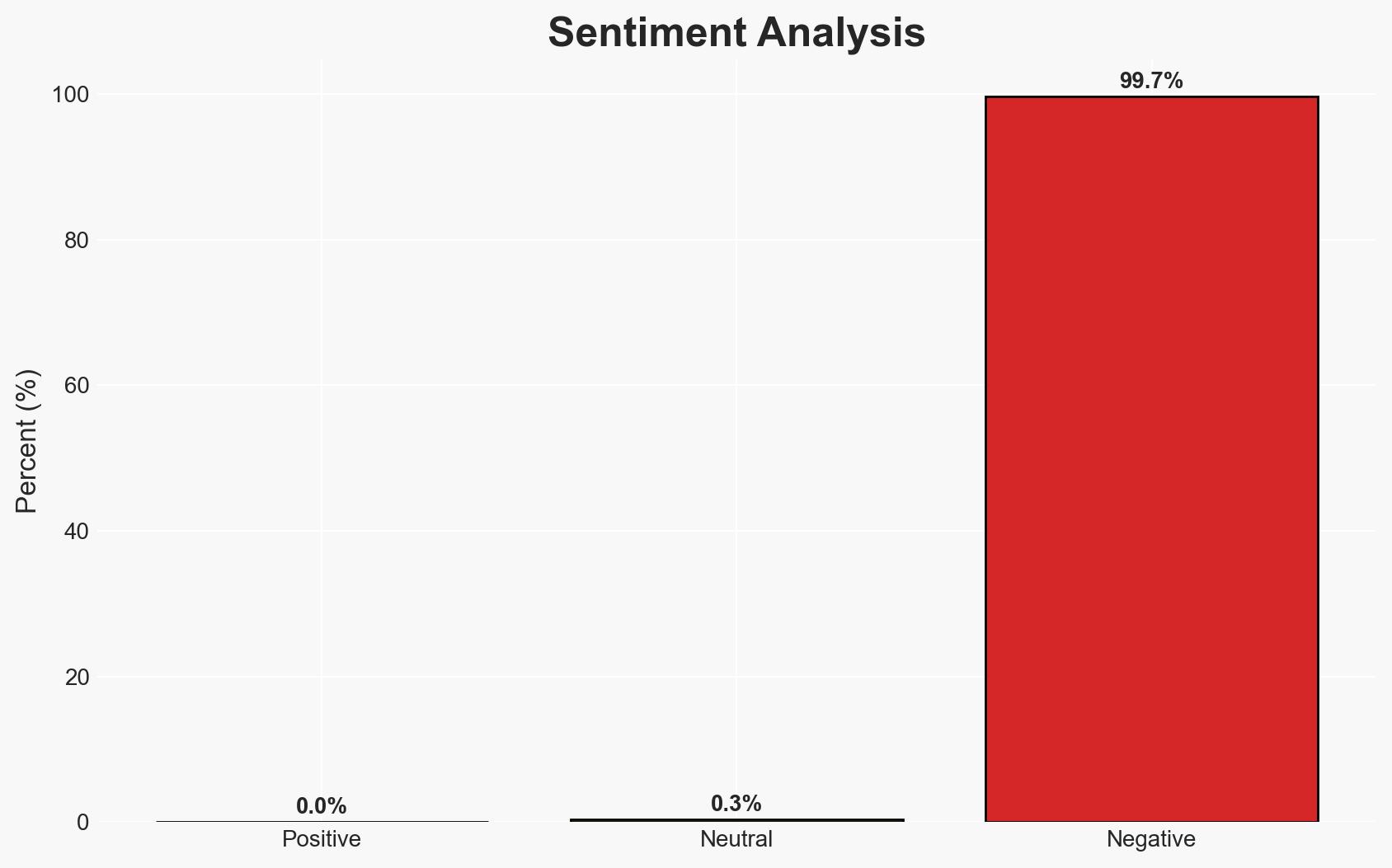
- Bias & Deception Risks: Potential bias in the report from Phantom Labs as a security company; lack of independent verification of the vulnerability’s exploitation.
4. Implications and Strategic Risks
This incident highlights the evolving security landscape as AI tools become more integrated into software development, potentially increasing the attack surface for cyber threats.
- Political / Geopolitical: Limited direct implications, but could influence policy discussions on AI and cybersecurity standards.
- Security / Counter-Terrorism: Raises awareness of AI-related vulnerabilities, potentially prompting increased scrutiny and security measures in tech environments.
- Cyber / Information Space: Demonstrates the need for robust security protocols in AI-driven environments to prevent exploitation and data breaches.
- Economic / Social: Potential reputational impact on OpenAI and trust in AI tools, influencing adoption rates and investment in AI technologies.
5. Recommendations and Outlook
- Immediate Actions (0–30 days): Conduct a thorough audit of AI integration points in development workflows; enhance monitoring for unusual activities related to AI tools.
- Medium-Term Posture (1–12 months): Develop partnerships with cybersecurity firms for continuous vulnerability assessment; invest in training for secure AI deployment practices.
- Scenario Outlook: Best: Enhanced security measures prevent future incidents; Worst: Undetected vulnerabilities lead to significant breaches; Most-Likely: Incremental improvements in AI security practices with occasional vulnerabilities.
6. Key Individuals and Entities
- OpenAI Group PBC
- Phantom Labs (BeyondTrust Corp.)
- GitHub (as a platform affected by the vulnerability)
7. Thematic Tags
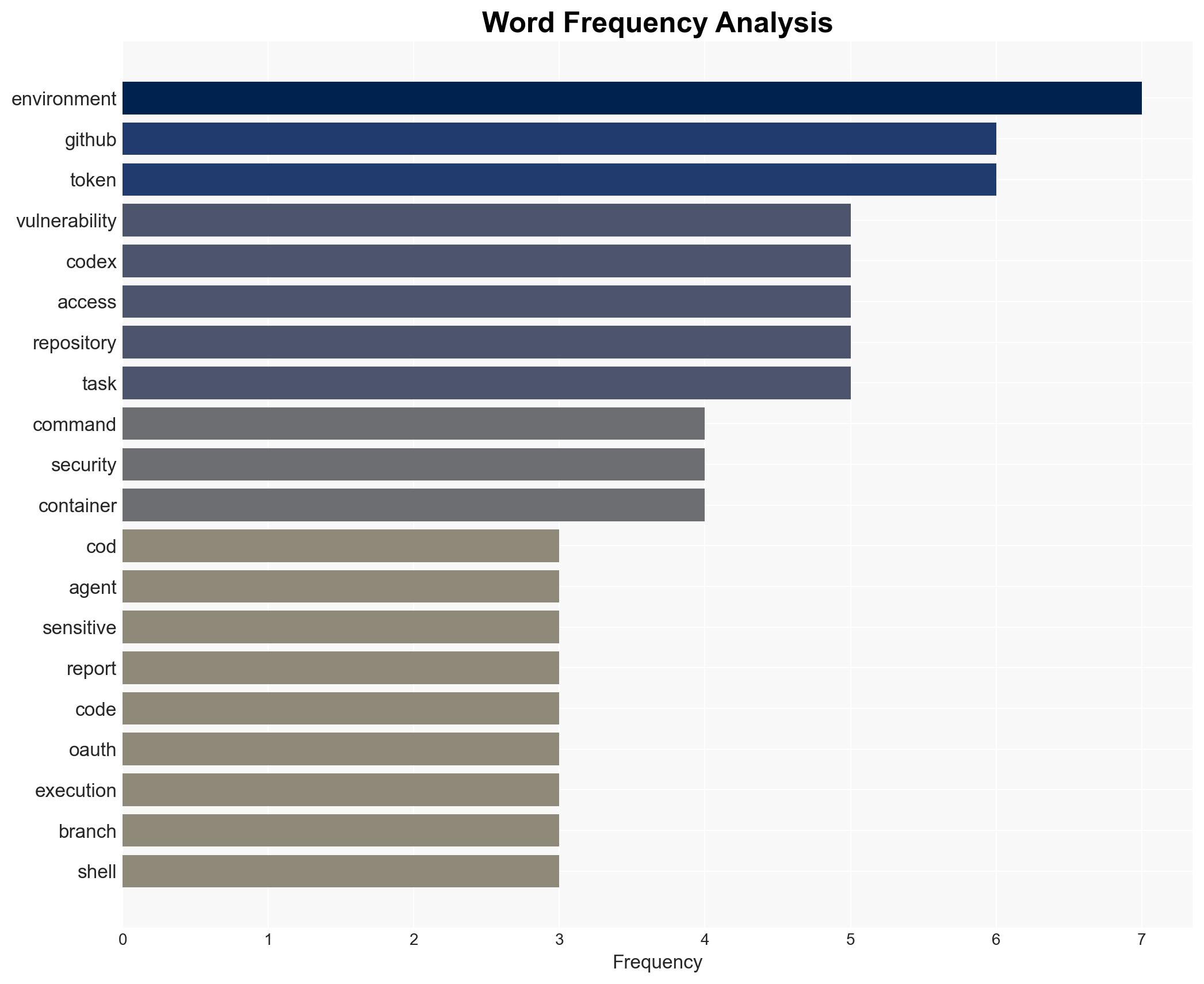
cybersecurity, AI integration, vulnerability management, software development, GitHub, command injection, OpenAI
Structured Analytic Techniques Applied
- Adversarial Threat Simulation: Model and simulate actions of cyber adversaries to anticipate vulnerabilities and improve resilience.
- Indicators Development: Detect and monitor behavioral or technical anomalies across systems for early threat detection.
- Bayesian Scenario Modeling: Quantify uncertainty and predict cyberattack pathways using probabilistic inference.
- Network Influence Mapping: Map influence relationships to assess actor impact.
Explore more:
Cybersecurity Briefs ·
Daily Summary ·
Support us