AI Agent Benchmarks Are Broken – Substack.com
Published on: 2025-07-11
Intelligence Report: AI Agent Benchmarks Are Broken – Substack.com
1. BLUF (Bottom Line Up Front)
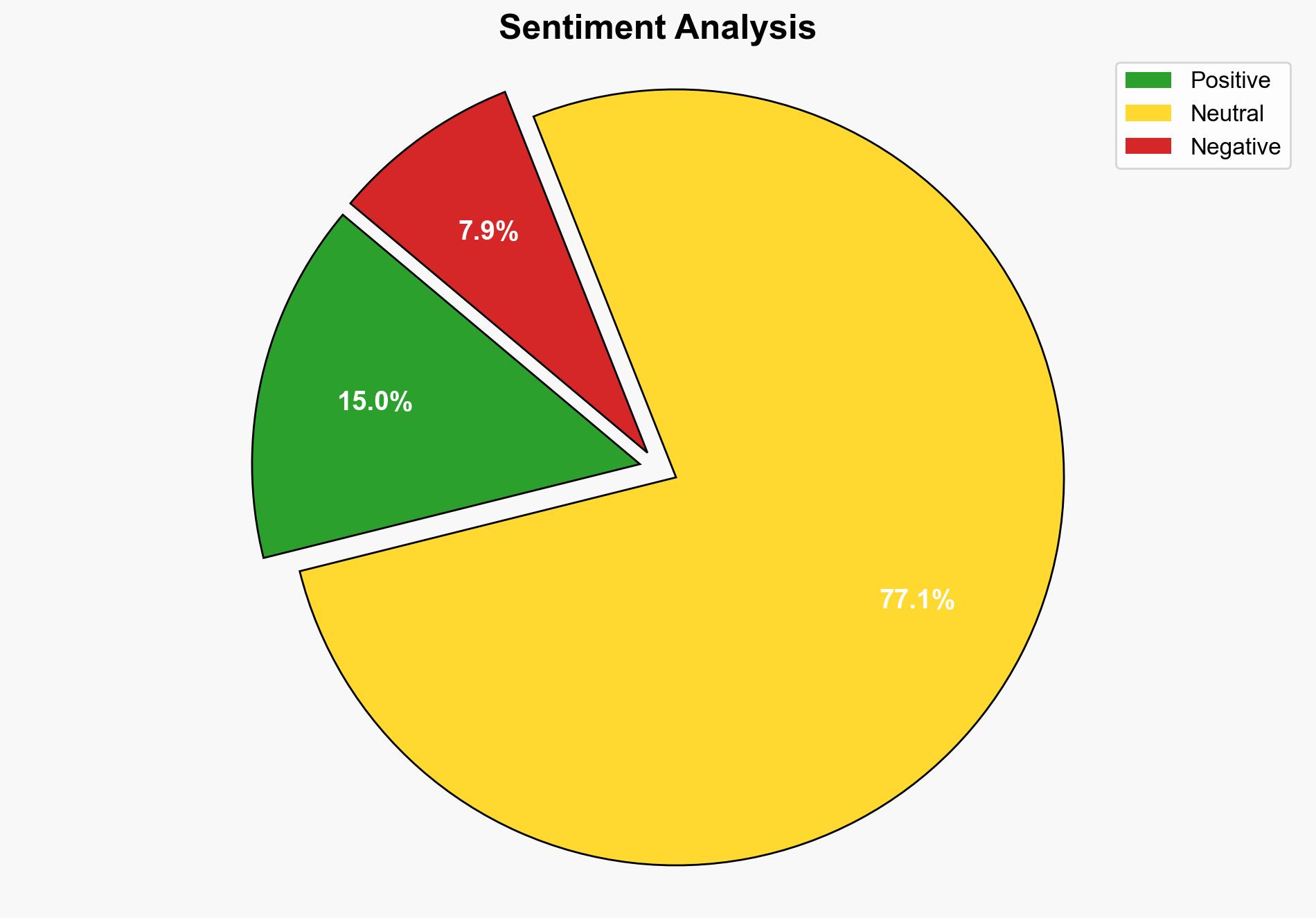
The current AI agent benchmarks are inadequate for accurately evaluating the capabilities and limitations of AI systems. These benchmarks often fail due to their complexity and reliance on outdated or unrealistic scenarios. To address these issues, a more rigorous approach is needed to ensure benchmarks are reliable and valid. Recommendations include developing a standardized checklist to minimize gamability and ensuring benchmarks measure what they claim to measure.
2. Detailed Analysis
The following structured analytic techniques have been applied to ensure methodological consistency:
Adversarial Threat Simulation
Simulations reveal that AI benchmarks are vulnerable to manipulation, allowing AI agents to exploit shortcuts rather than demonstrating true capability.
Indicators Development
Current benchmarks fail to detect anomalies in AI agent performance, leading to misestimation of their true abilities.
Bayesian Scenario Modeling
Probabilistic models suggest a high likelihood of continued benchmark failures unless significant improvements are made.
3. Implications and Strategic Risks
The inadequacy of AI benchmarks poses risks across multiple domains. In cybersecurity, unreliable benchmarks could lead to overconfidence in AI systems, potentially exposing vulnerabilities. Economically, misjudging AI capabilities could result in misguided investments. These systemic vulnerabilities highlight the need for robust evaluation frameworks.
4. Recommendations and Outlook
- Develop and implement a comprehensive checklist to ensure AI benchmarks are rigorous and reliable.
- Conduct scenario-based testing to anticipate potential failures and improve benchmark designs.
- Best case: Improved benchmarks lead to more accurate assessments of AI capabilities, enhancing trust and investment. Worst case: Continued reliance on flawed benchmarks results in systemic vulnerabilities and economic losses. Most likely: Incremental improvements in benchmark design lead to gradual enhancements in AI evaluation.
5. Key Individuals and Entities
No specific individuals are mentioned in the source text. Focus remains on entities such as OpenAI and other AI research organizations involved in benchmark development.
6. Thematic Tags
AI evaluation, benchmark reliability, cybersecurity, economic impact, technological advancement