I Asked OpenAIs New Open-Source LLM to Complete a Test Designed for Children Is It Smarter Than a 10-Year-Old – Windows Central
Published on: 2025-08-10
Intelligence Report: I Asked OpenAIs New Open-Source LLM to Complete a Test Designed for Children Is It Smarter Than a 10-Year-Old – Windows Central
1. BLUF (Bottom Line Up Front)
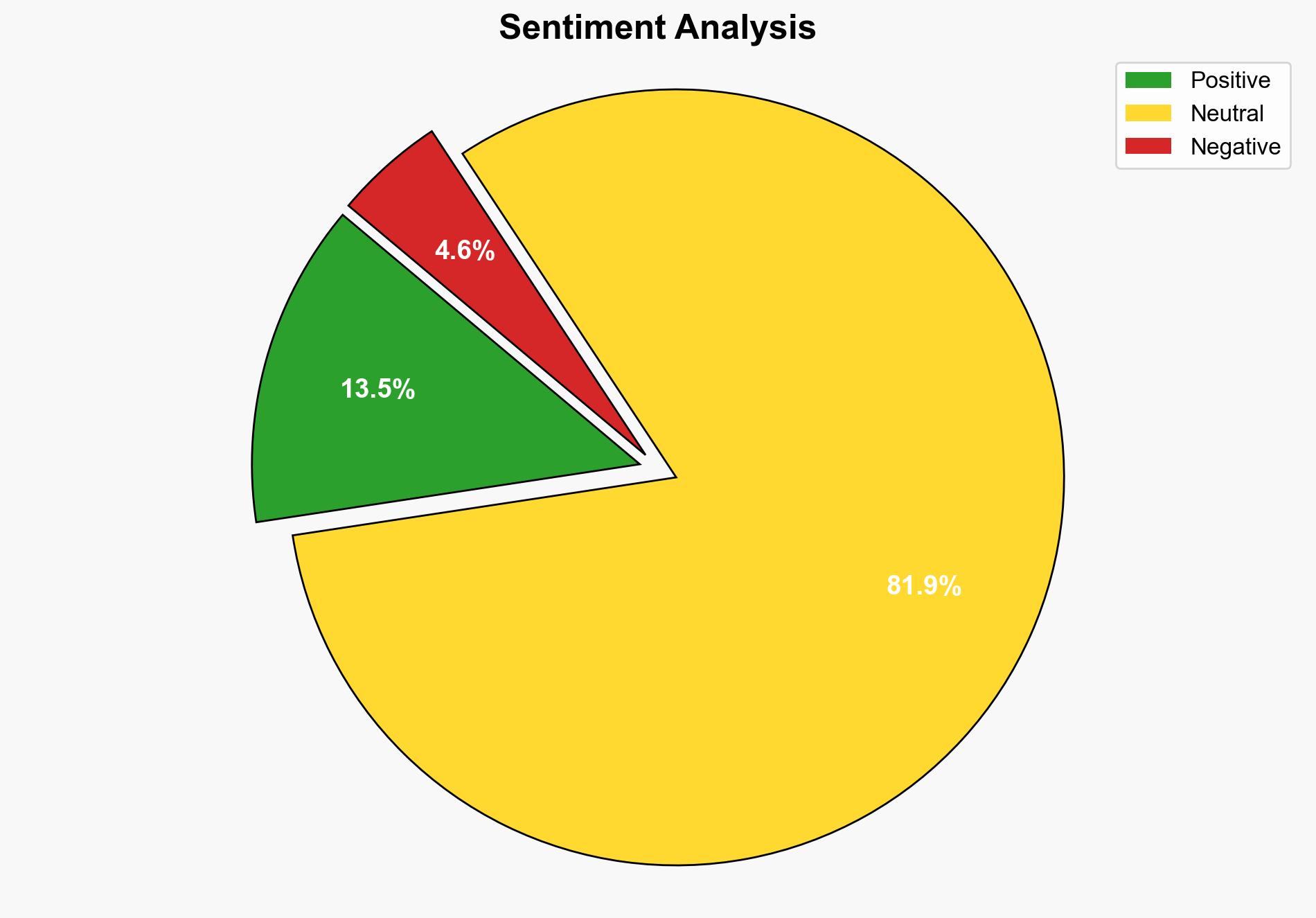
The analysis suggests that OpenAI’s new open-source language model (LLM) struggles with tasks designed for children, indicating limitations in its reasoning and contextual understanding capabilities. The most supported hypothesis is that the model’s performance is constrained by its training data and inherent design limitations. Confidence level: Moderate. Recommended action: Further refinement of the model’s training data and algorithms to enhance contextual comprehension and reasoning abilities.
2. Competing Hypotheses
1. **Hypothesis A**: The LLM’s poor performance on the children’s test is due to insufficient training data that aligns with the specific context and reasoning required for such tasks.
2. **Hypothesis B**: The LLM’s architecture inherently limits its ability to perform tasks that require a deep understanding of context and reasoning, irrespective of the training data.
Using ACH 2.0, Hypothesis A is better supported as the model’s performance could potentially improve with more targeted training data, whereas architectural limitations would require more fundamental changes.
3. Key Assumptions and Red Flags
– **Assumptions**: It is assumed that the LLM’s architecture is capable of improvement with better data. It is also assumed that the test accurately reflects the model’s reasoning capabilities.
– **Red Flags**: The test results may not fully represent the model’s capabilities in other contexts. Additionally, the evaluation criteria for “smartness” may be subjective.
4. Implications and Strategic Risks
The model’s limitations could impact its deployment in educational and child-focused applications, potentially leading to user dissatisfaction. There is a risk of overestimating the model’s capabilities in critical applications, which could lead to strategic missteps in AI deployment strategies.
5. Recommendations and Outlook
- Enhance the model’s training data with more contextually relevant examples to improve performance on reasoning tasks.
- Conduct further testing across different domains to identify specific areas for improvement.
- Best-case scenario: The model’s performance improves significantly with targeted training. Worst-case scenario: Architectural limitations prevent meaningful improvements. Most likely scenario: Incremental improvements with ongoing refinement.
6. Key Individuals and Entities
– OpenAI
– Windows Central (as the source of the report)
7. Thematic Tags
artificial intelligence, machine learning, educational technology, model training, contextual reasoning