Is Meta Scraping the Fediverse for AI – Wedistribute.org
Published on: 2025-08-13
Intelligence Report: Is Meta Scraping the Fediverse for AI – Wedistribute.org
1. BLUF (Bottom Line Up Front)
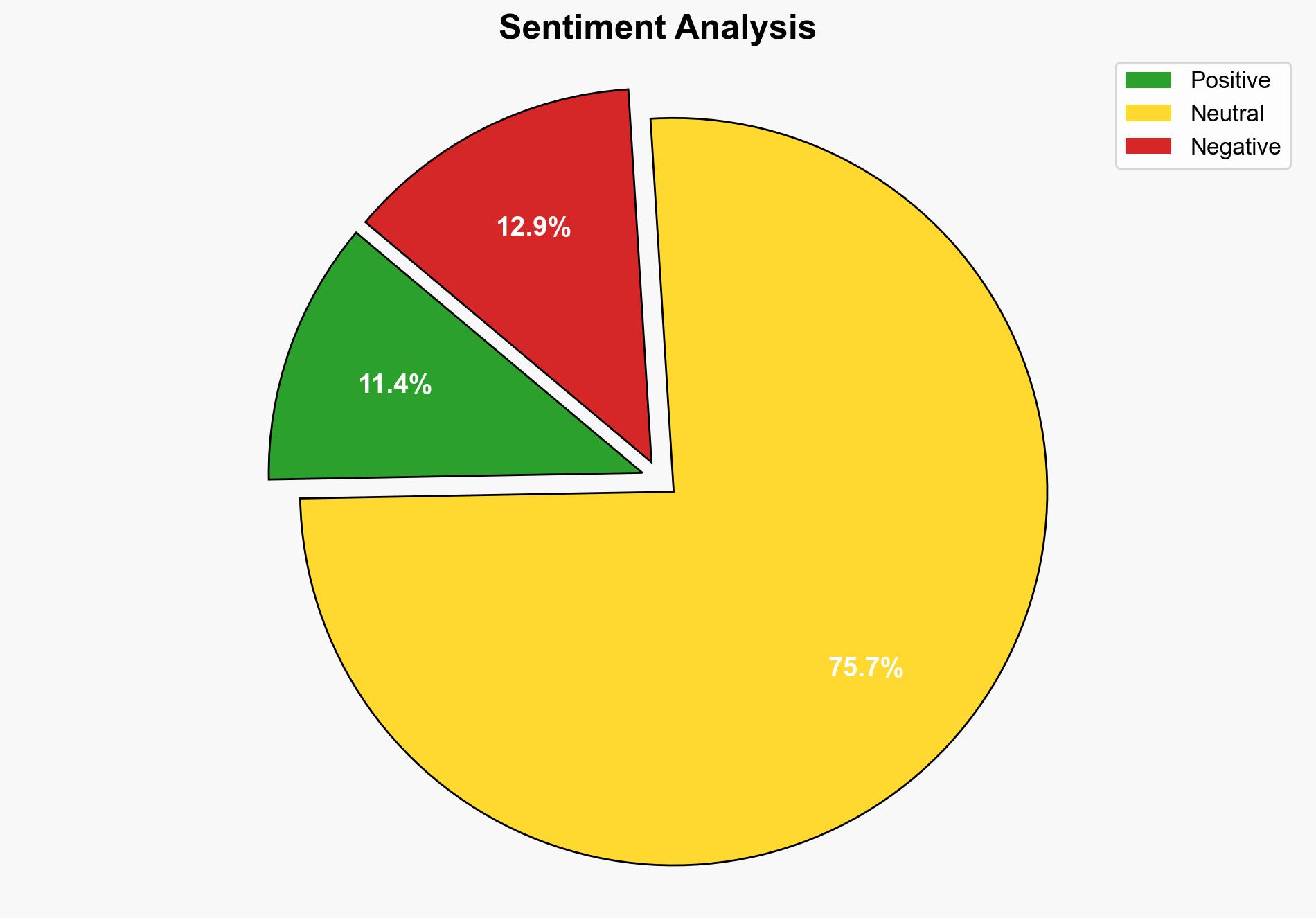
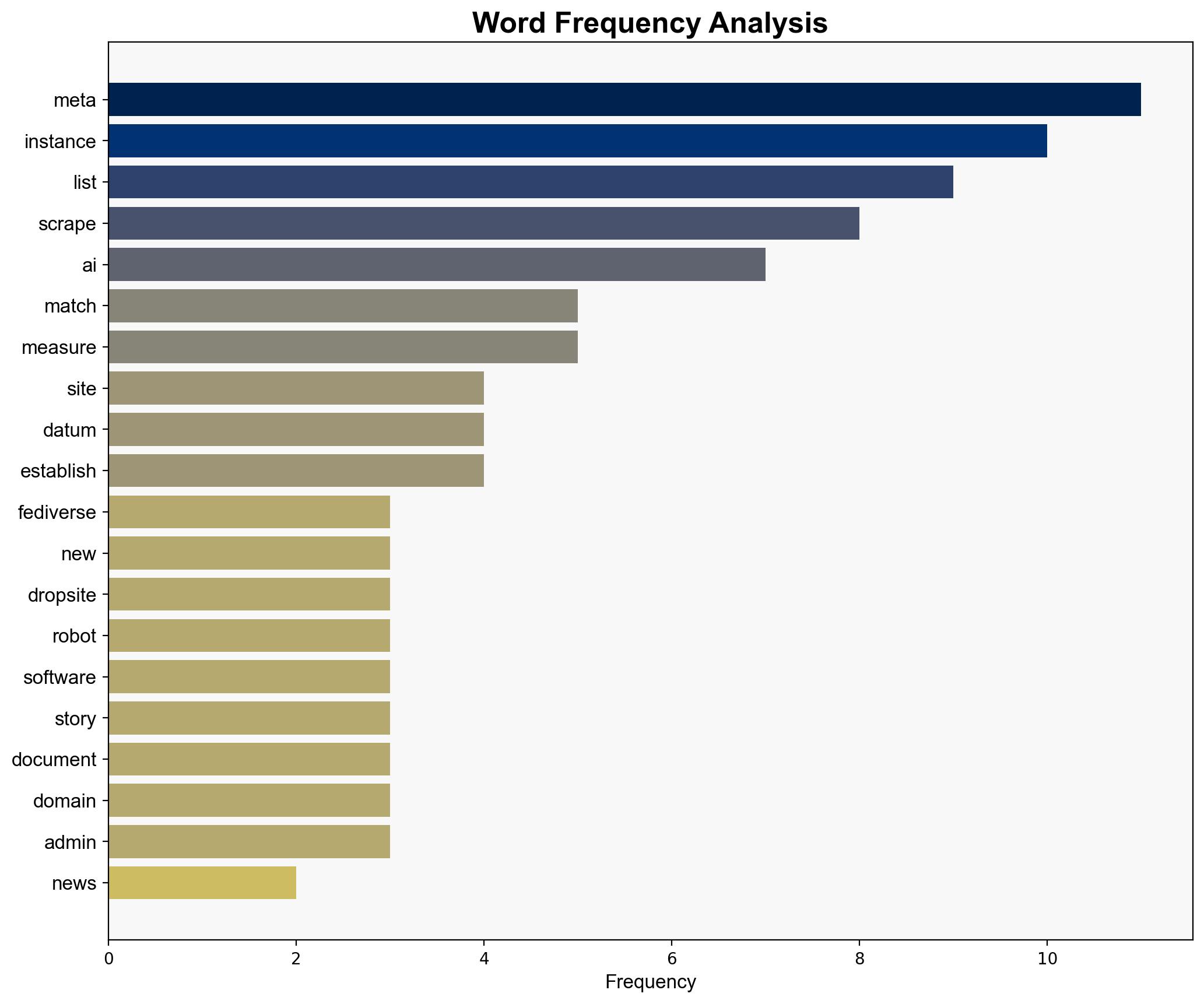
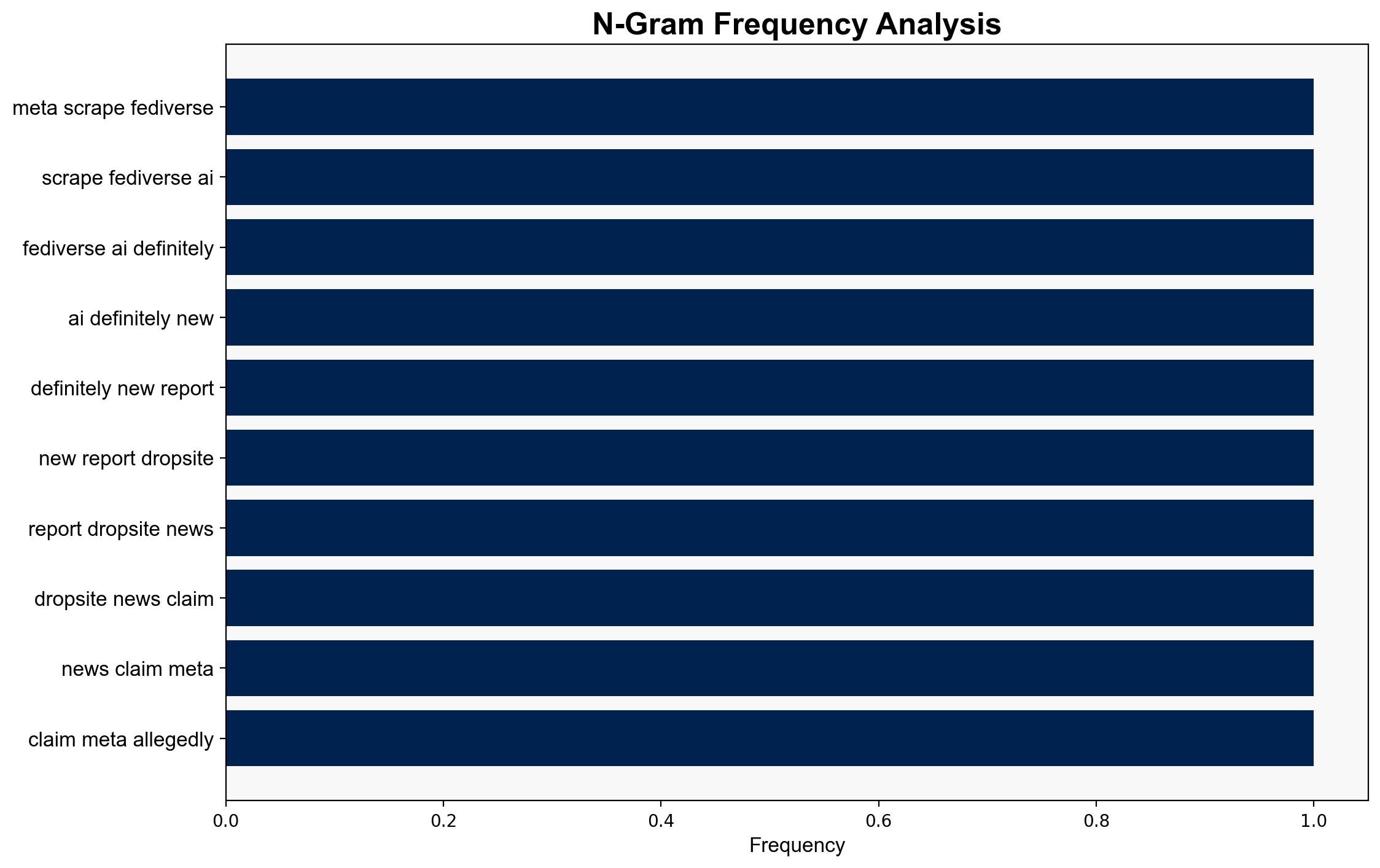
Meta is allegedly scraping data from the Fediverse to train AI models, raising privacy and ethical concerns. The most supported hypothesis is that Meta is engaging in data scraping activities, albeit possibly within legal boundaries. Confidence level is moderate due to lack of direct evidence. Recommended action includes monitoring Meta’s data practices and advocating for clearer data protection regulations.
2. Competing Hypotheses
Hypothesis 1: Meta is actively scraping the Fediverse for AI training purposes, disregarding robots.txt and other data protection measures.
Hypothesis 2: Meta is not scraping the Fediverse; the allegations are based on misinterpretations or misinformation, and Meta’s data collection practices are compliant with existing regulations.
Using ACH 2.0, Hypothesis 1 is better supported by the pattern of Meta’s historical data collection practices and the lack of a strong public denial. However, the absence of direct evidence and Meta’s official denial lend some support to Hypothesis 2.
3. Key Assumptions and Red Flags
Assumptions:
– Hypothesis 1 assumes Meta has the technical capability and intent to scrape the Fediverse.
– Hypothesis 2 assumes Meta’s denial is truthful and that existing data protection measures are effective.
Red Flags:
– Lack of direct evidence or whistleblower testimony.
– Meta’s denial could be a strategic communication to mitigate reputational damage.
– Potential bias in the source, as the report is from a smaller, possibly less vetted outlet.
4. Implications and Strategic Risks
If Hypothesis 1 is true, it could lead to increased scrutiny and regulatory action against Meta, affecting its operations and market perception. It may also prompt other tech companies to follow suit, exacerbating privacy concerns. Conversely, if Hypothesis 2 is accurate, the risk lies in undermining public trust in media reporting and regulatory bodies.
5. Recommendations and Outlook
- Monitor Meta’s data practices and advocate for transparency in AI training data sources.
- Engage with policymakers to establish clearer regulations on data scraping and AI training.
- Scenario Projections:
- Best Case: Meta clarifies its data practices, leading to improved industry standards.
- Worst Case: Escalation of privacy violations, resulting in significant regulatory penalties.
- Most Likely: Continued ambiguity and debate over data scraping practices.
6. Key Individuals and Entities
Andy Stone, communications representative for Meta, is a key figure in addressing these allegations.
7. Thematic Tags
cybersecurity, data privacy, AI ethics, corporate governance, regulatory compliance