Simple Text Additions Can Fool Advanced AI Reasoning Models Researchers Find – Slashdot.org
Published on: 2025-07-04
Intelligence Report: Simple Text Additions Can Fool Advanced AI Reasoning Models Researchers Find – Slashdot.org
1. BLUF (Bottom Line Up Front)
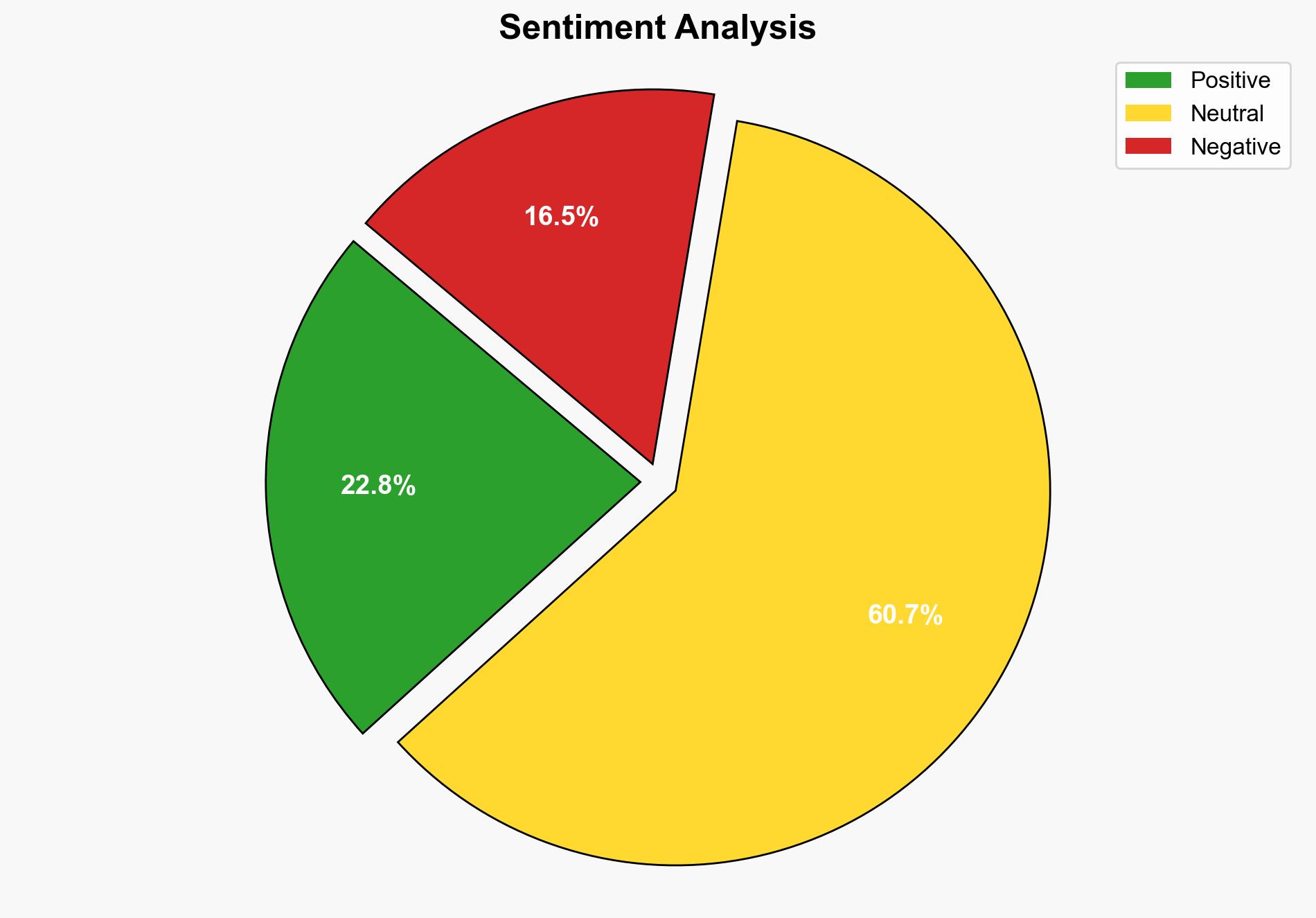
Recent research highlights a vulnerability in advanced AI reasoning models, where simple text additions can significantly degrade performance. This discovery, termed “Catattack,” demonstrates that appending irrelevant phrases to inputs can lead to incorrect answers and increased computational costs. The findings suggest a need for enhanced security measures to protect AI systems from adversarial attacks.
2. Detailed Analysis
The following structured analytic techniques have been applied to ensure methodological consistency:
Adversarial Threat Simulation
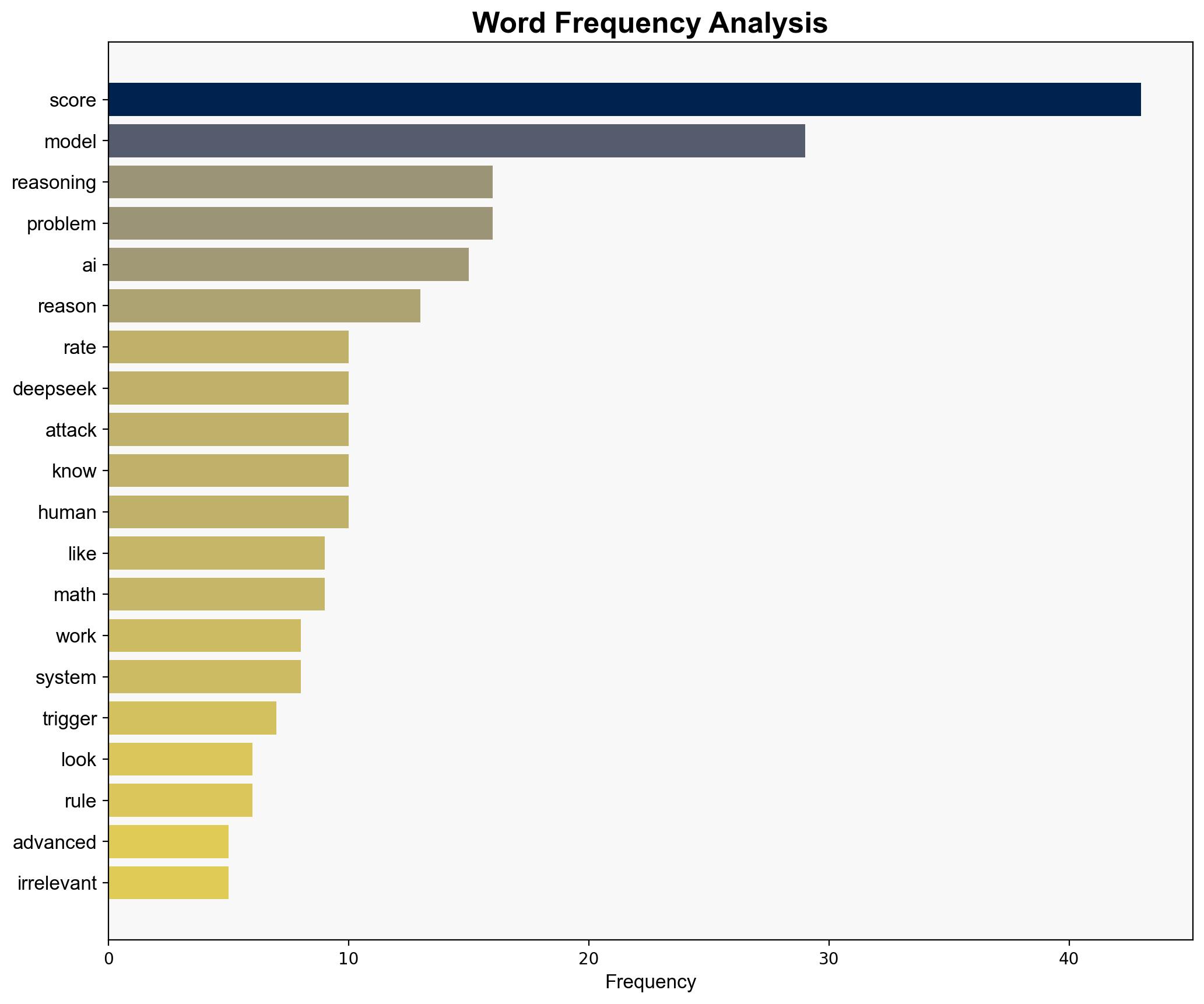
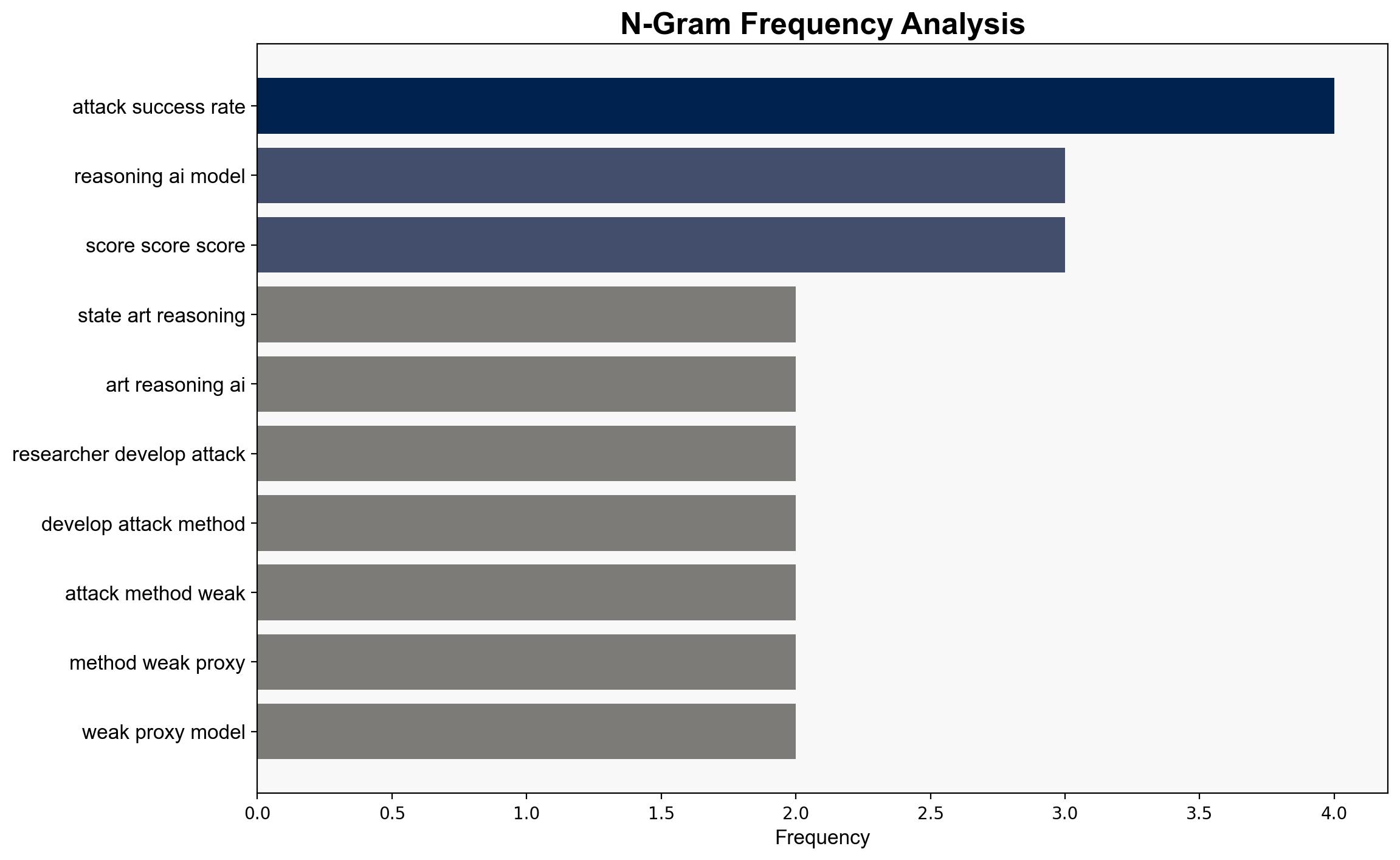
Researchers simulated adversarial conditions by appending irrelevant text to mathematical problems, revealing vulnerabilities in AI reasoning models such as DeepSeek and OpenAI’s family.
Indicators Development
Key indicators include increased error rates and prolonged response times in AI models when subjected to adversarial text triggers.
Bayesian Scenario Modeling
Probabilistic modeling suggests a high likelihood of similar vulnerabilities in other AI systems, highlighting potential pathways for cyberattacks.
3. Implications and Strategic Risks
The ability to exploit AI reasoning models poses significant cybersecurity risks, potentially affecting sectors reliant on AI for decision-making. The cascading effects could undermine trust in AI systems and lead to broader systemic vulnerabilities, particularly in critical infrastructure and national security applications.
4. Recommendations and Outlook
- Develop robust adversarial defenses and detection mechanisms to safeguard AI systems from text-based attacks.
- Conduct regular vulnerability assessments and stress tests on AI models to identify and mitigate potential weaknesses.
- Scenario-based projections suggest that without intervention, adversarial attacks could become more sophisticated, increasing the risk of widespread disruption.
5. Key Individuals and Entities
The research was conducted by a team from Stanford University and ServiceNow, including the DeepSeek model developers. Specific individuals were not named in the source material.
6. Thematic Tags
national security threats, cybersecurity, AI vulnerabilities, adversarial attacks